Hi friends in this session we'll deal Data Structures. In this session following are the Data Structures, going to be covered:
1. Arrays
2. List
3. Set
4. Stack
5. Queue
6. Trees
7. Graphs
We would be enjoying the implementation of the above said Data Structures, but since we'll be dealing too many examples for each Structure. It would be better if we dedicate separate post for each Data Structure. In this post we would look at each Data Structure briefly.
Arrays: Arrays are used for holding similar data types contiguously. Duplicate elements can exist.
Advantages - Holds elements in order.
Disadvantage - Size is fixed.
List: List is an interface, it helps us with number of classes implementing it, like LinkedList, ArrayList, Vectors. Usage of List is similar to Arrays, but in case of list we could increase size dynamically. Duplicate element can exist.
Advantages - Holds elements in order.
Set: Set is also an interface, it also provides number of classes implementing it, like SortedSet, HashSet, TreeSet etc. Elements in set remain Unique.
Note: From the above discussion we could consider the following things.
1. If you want some Data Structure which could hold elements in order, go for List or arrays.
2. If you want some Data Structure which could holds unique elements, use Sets.
3. For example if we need to remove duplicate elements in a list, we could insert all the elements in set, and again take the elements out of set. And insert them back to the list. Beware, you are losing the order in this process, since Set doesn't hold the order.
Hash: This is not a Data Structure, but is just a function. This helps in generating some unique id for a given input. This logic helps us in the creation of few beautiful Data Structures called HashSet, HashTable, HashMap. In general Hash function takes modulus of a given input and uses it as input index. Thus the above Data Structures works the following way:
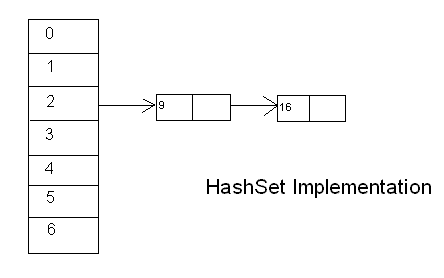
HashSet: This Data Structure places the elements in the index returned by the hash function. If the hash function returns same value for two different elements, the HashSet ideally creates a LinkedList and places both the elements contiguously. You could see that in the image below:

Note: If you want a Data Structure where addition of elements, deletion and fetching should be done as fast as possible you should think of using hash based Data Structures. Since that is expected to produce the results in O(1) complexity in time.
Suppose we have 'n' elements. And we use HashSet to add and retrieve these elements. Then the complexities are as follows:
Time: O(1)
Space: O(n)
Stack (First In Last Out): Here is one more beautiful Data Structure. Speaking informally Stack is like a ladies hand and elements are like bangles. Image if we could insert or retrieve bangles to/from ladies hand only one at a time. Now if she wears 10 bangles one after the other, starting from 1st bangle, next the 2nd one so on till 10th. For her to remove the 1st bangle she has to remove all the way till 2nd bangle starting from 10th bangle. Thus if the insertion series is 1, 2, 3, 4,5, 6,7,8,9,10 then the removal series will be 10,9,8,7,6,5,4,3,2,1.
usage: The most famous usage of stack can be found in any text editor. Suppose we are typing a letter and if we would like to undo the changes made. We all knew the famous Ctrl+Z, to be used. Do we expect the undo to revert back to the change made just now, or do we expect it to undo the first change made. Obviously the changes just made. Thus every Data Structure has some important position in programming.
Queues (First In First Out): Queue Data Structure is like my wife's memory. When every we argue with each other. She starts digging my mistakes right from the day one till the present mistake. Don't know how could she remember those many.
Trees: Tress are special Data Structures which hold connection between elements in a peculiar way. Here one or more elements are connected to a single node called Parent-node and these connected nodes are called Child-nodes. A child node can be a parent node to elements which are not yet added to the tree. Below is an image explaining Tree:

Terminology:
Root Node: A node which is not derived from any of the node in a given tree is called Root node. Here it is element 'A'
Child Node: Child node can be identified with respect to its parent. Thus Child Nodes of element 'A' are B and C. And child nodes of B are D and E. In case of Parent C there is only one Child 'F'.
Leaf Node: Node without any child node are said to be leaf nodes. example D,E and F.
Binary Tree: A tree with a condition that every element in it can at most have 2 child nodes (never more than 2 child nodes)
Note: No element can be child of 2 different parent nodes. i.e., there can be only one parent for a given element, unless it is a root node, in which case there is no parent node.
Number of types of Trees need to be cover like Binary-Search Tree etc. Which are going to be dealt in a separate post specific to Trees.
Graphs: In Graphs connection is possible between any element to any element. An element can be connected to more than one element. We would be covering Graphs in details with different problems and algorithms like dijkstra's algorithms, minimal spanning tree etc.
1. Arrays
2. List
3. Set
4. Stack
5. Queue
6. Trees
7. Graphs
We would be enjoying the implementation of the above said Data Structures, but since we'll be dealing too many examples for each Structure. It would be better if we dedicate separate post for each Data Structure. In this post we would look at each Data Structure briefly.
Arrays: Arrays are used for holding similar data types contiguously. Duplicate elements can exist.
Advantages - Holds elements in order.
Disadvantage - Size is fixed.
List: List is an interface, it helps us with number of classes implementing it, like LinkedList, ArrayList, Vectors. Usage of List is similar to Arrays, but in case of list we could increase size dynamically. Duplicate element can exist.
Advantages - Holds elements in order.
Set: Set is also an interface, it also provides number of classes implementing it, like SortedSet, HashSet, TreeSet etc. Elements in set remain Unique.
Note: From the above discussion we could consider the following things.
1. If you want some Data Structure which could hold elements in order, go for List or arrays.
2. If you want some Data Structure which could holds unique elements, use Sets.
3. For example if we need to remove duplicate elements in a list, we could insert all the elements in set, and again take the elements out of set. And insert them back to the list. Beware, you are losing the order in this process, since Set doesn't hold the order.
Hash: This is not a Data Structure, but is just a function. This helps in generating some unique id for a given input. This logic helps us in the creation of few beautiful Data Structures called HashSet, HashTable, HashMap. In general Hash function takes modulus of a given input and uses it as input index. Thus the above Data Structures works the following way:
HashSet: This Data Structure places the elements in the index returned by the hash function. If the hash function returns same value for two different elements, the HashSet ideally creates a LinkedList and places both the elements contiguously. You could see that in the image below:
Note: If you want a Data Structure where addition of elements, deletion and fetching should be done as fast as possible you should think of using hash based Data Structures. Since that is expected to produce the results in O(1) complexity in time.
Suppose we have 'n' elements. And we use HashSet to add and retrieve these elements. Then the complexities are as follows:
Time: O(1)
Space: O(n)
Stack (First In Last Out): Here is one more beautiful Data Structure. Speaking informally Stack is like a ladies hand and elements are like bangles. Image if we could insert or retrieve bangles to/from ladies hand only one at a time. Now if she wears 10 bangles one after the other, starting from 1st bangle, next the 2nd one so on till 10th. For her to remove the 1st bangle she has to remove all the way till 2nd bangle starting from 10th bangle. Thus if the insertion series is 1, 2, 3, 4,5, 6,7,8,9,10 then the removal series will be 10,9,8,7,6,5,4,3,2,1.
usage: The most famous usage of stack can be found in any text editor. Suppose we are typing a letter and if we would like to undo the changes made. We all knew the famous Ctrl+Z, to be used. Do we expect the undo to revert back to the change made just now, or do we expect it to undo the first change made. Obviously the changes just made. Thus every Data Structure has some important position in programming.
Queues (First In First Out): Queue Data Structure is like my wife's memory. When every we argue with each other. She starts digging my mistakes right from the day one till the present mistake. Don't know how could she remember those many.
Trees: Tress are special Data Structures which hold connection between elements in a peculiar way. Here one or more elements are connected to a single node called Parent-node and these connected nodes are called Child-nodes. A child node can be a parent node to elements which are not yet added to the tree. Below is an image explaining Tree:

Terminology:
Root Node: A node which is not derived from any of the node in a given tree is called Root node. Here it is element 'A'
Child Node: Child node can be identified with respect to its parent. Thus Child Nodes of element 'A' are B and C. And child nodes of B are D and E. In case of Parent C there is only one Child 'F'.
Leaf Node: Node without any child node are said to be leaf nodes. example D,E and F.
Binary Tree: A tree with a condition that every element in it can at most have 2 child nodes (never more than 2 child nodes)
Note: No element can be child of 2 different parent nodes. i.e., there can be only one parent for a given element, unless it is a root node, in which case there is no parent node.
Number of types of Trees need to be cover like Binary-Search Tree etc. Which are going to be dealt in a separate post specific to Trees.
Graphs: In Graphs connection is possible between any element to any element. An element can be connected to more than one element. We would be covering Graphs in details with different problems and algorithms like dijkstra's algorithms, minimal spanning tree etc.
"This blog post provides a detailed analysis of the DSE's academic programs and faculty. It's a great resource for anyone interested in pursuing higher studies in economics. Check it out: https://vataliya-computer.blogspot.com/2024/09/dse.html
ReplyDelete